Optimizing Rabin-Karp Hashing
02 Mar 2024Intro
Daniel Lemire is a professor of computer science at TÉLUQ, who specializes in performance engineering. He is also a prolific blogger, and his posts are occasionally featured on Hacker News. If you somehow found your way to this blog, you are likely familiar with his writing. A few weeks ago, he posed the following question: “How fast is rolling Rabin-Karp hashing?”, for example as might be used in the Rabin-Karp string search algorithm.
A friend and I had some extra time over the past couple of days, and we figured it would be fun to explore the problem. As it turns out, the algorithm is a good way to build an understanding for low-level performance optimizations, in particular the role of dependency chain latency.
If you haven’t read Lemire’s post yet, I would suggest at least giving it a quick glance.
Notes
I should point out a few things about the benchmarking code provided by Lemire, that you might find useful if you decide to experiment yourself:
-
The choice of window sizes does not reflect any real world scenario (if the target string is 8 bytes, we can just load and compare the whole string in a normal register). In our benchmarks we used much larger values.
-
The reported throughput is the maximum recorded throughput per run. This isn’t necessarily a bad choice, but it can make the result a bit unstable. We changed that to reflect the average throughput over all runs. No results were substantially affected by this change.
-
The choice of \(31\) as the default evaluation point for the polynomial means that if the method gets inlined, and your compiler is aggressive enough (as clang is), you can end up with a highly specialized and very fast implementation being emitted that elides the multiplications (
x*31 => (x << 5) - x), and which will confound all of your benchmarks. Lemire seems to be aware of this, and has__attribute__(noinline)everywhere. If you want to add methods to experiment with using his test harness, you’ll want to make sure to add that attribute to those methods. -
I have tried to stay aligned with the conventions and naming from Lemire’s code. This may lead to some strange-looking style mismatches in the code.
Notation and Setup
To stay aligned with Lemire’s benchmarks, we will reuse the signature from his code:
size_t count_hits(
const char *data,
size_t input_length,
size_t window_length,
uint32_t B,
uint32_t target
);
This counts the number of substrings of window_lengthwithin the input string that match the target hashcode. While it is not a particularly useful method, it does force us to compute and use the hashes.
For reference, all benchmarks were run on a Intel Xeon Platinum 8481C CPU (Sapphire Rapids).
Naive Approach
I won’t dwell on the naive approach too much, except to introduce the notation we’ll use throughout:
-
The length of the input to be searched is \(n\). In the source code, we use the variable
lento represent this. -
The window length, \(w\), is the length of the target string. Somewhat confusingly, in much of the source code, we use the variable
Nto represent this (this is from the original benchmark code). -
The input data array will either be referred to as
dataor asa. The latter comes from thinking of the input as an array \([a_0,a_1,...,a_{n-1}]\), or from the hash code as the series, for example \(a_0+a_1B+a_2B^2+...+a_{w-1}B^{w-1}\). -
The base is \(B\).
The naive approach takes time \(O(nw)\). We can’t even really benchmark it, as it very quickly becomes intractable to run.
Simple Rolling Approach
Again, I won’t dwell on this too much, except to paste the reference code, and establish a baseline benchmark. I’ll also point out that this algorithm is asymptotically optimal (requiring only a constant amount of work per input item), and uses O(w) memory.
Here’s the code from Lemire’s post:
__attribute__ ((noinline))
size_t karprabin_rolling(const char *data, size_t len, size_t N, uint32_t B, uint32_t target) {
size_t counter = 0;
uint32_t BtoN = 1;
for (size_t i = 0; i < N; i++) {
BtoN *= B;
}
uint32_t hash = 0;
for (size_t i = 0; i < N; i++) {
hash = hash * B + data[i];
}
if (hash == target) {
counter++;
}
for (size_t i = N; i < len; i++) {
hash = hash * B + data[i] - BtoN * data[i - N];
if (hash == target) {
counter++;
}
}
return counter;
}
This runs at 0.73 GB/s.
Thinking about performance
Tools like perf are great. But in my experience, it’s useful to try to form a hypothesis before breaking out a profiler. This helps ground the process, and forces us to develop and update a mental model of the performance of the code as we investigate. I’ve also found this general approach to be useful at other scales (for example when analyzing bottlenecks in distributed systems).
A good starting point is to be able to bound the problem in some way. So with that in mind, let’s throw together a quick benchmark for computing the simpler hash function, that’s just a sum of the values over the sliding window (you could think of this as a Rabin-Karp hash with \(B=1\)):
__attribute__ ((noinline))
size_t sum_rolling(const char *data, size_t len, size_t N, uint32_t B, uint32_t target) {
size_t counter = 0;
uint32_t hash = 0;
for (size_t i = 0; i < N; i++) {
hash = hash + data[i];
}
if (hash == target) {
counter++;
}
for (size_t i = N; i < len; i++) {
hash = hash + data[i] - data[i - N];
if (hash == target) {
counter++;
}
}
return counter;
}
This runs at 1.49 GB/s.
Returning to our actual problem, let’s try to build an intuition for where the opportunities to optimize lie. Consider the instructions that are executed on each loop iteration:
-
Load two values (the incoming and outgoing elements).
-
Multiply the outgoing element by \(B^n\).
-
Multiply the hash by \(B\).
-
Add the incoming element and subtract the (scaled) outgoing element to the hash.
-
Do some bounds checking, update loop variables, etc..
On one hand, this seems pretty good. Multiplication on Sapphire Rapids has a latency of 4 cycles. This core is clocked (when boosted) at 3.8GHz, so this implementation is processing one item every 5 ticks. We could try to squeeze out a little bit more performance by manually unrolling the loop (as Lemire does in his reference code). In our case, that doesn’t make any difference, because the compiler has already helpfully unrolled the loop for us.
The bigger issue is that we have a lot of idle silicon sitting around. And the cause of this is the dependency chain between the hash code computations. For example, the first three hashes are:
\[\begin{align*} &H_0=... \\ &H_1 = B*H_0 + ... \\ &H_2 = B*H_1 + ... \end{align*}\]We clearly cannot start to compute \(H_2\) before we have computed \(H_1\), and so must wait to issue the multiplication \(B*H_1\) until we have computed \(H_1\), which involves computing \(B*H_0\), which takes at least 4 cycles. This is what’s known as a loop-carried dependency. The processor can try to stay busy by executing the other operations while the multiply is running, but ultimately the latency of the multiplication puts a limit on the overall throughput.
To see this, I find it helpful to draw out the computation graph over time (here is a very good overview of the general technique). Time flows downward, and arrows represent data dependencies between instructions. I’ve drawn out part of an iteration of an unrolled loop (I only included the loads for two windows to avoid cluttering things up too much). I’ve also highlighted the loop-carried dependency:
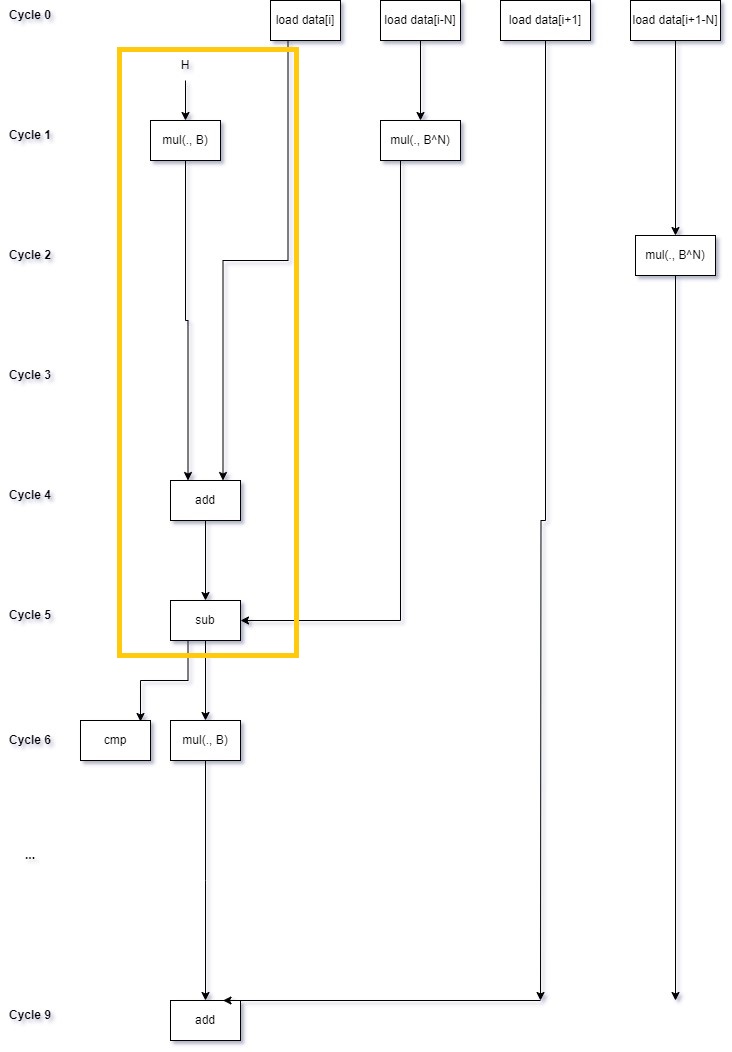
This may not line up exactly with the exact instructions that the processor executes in parallel, but does give the gist of it. Of particular note, you can see that the multiplications of the elements falling out of the window can be issued long before they are needed. It’s the dependency on multiplying the hash by \(B\) is the bottleneck.
“Parallelizing” the Process
One approach to getting around the chain dependency would be to simply split the input in half, and process each half in its own thread. Note that you have to do a little redundant work here. If we decide on the convention that each thread processes all hashes that begin within its half of the data, then the first thread needs to process an extra window’s worth of values.
Here’s an example of what the process might look like with a window of size 8:
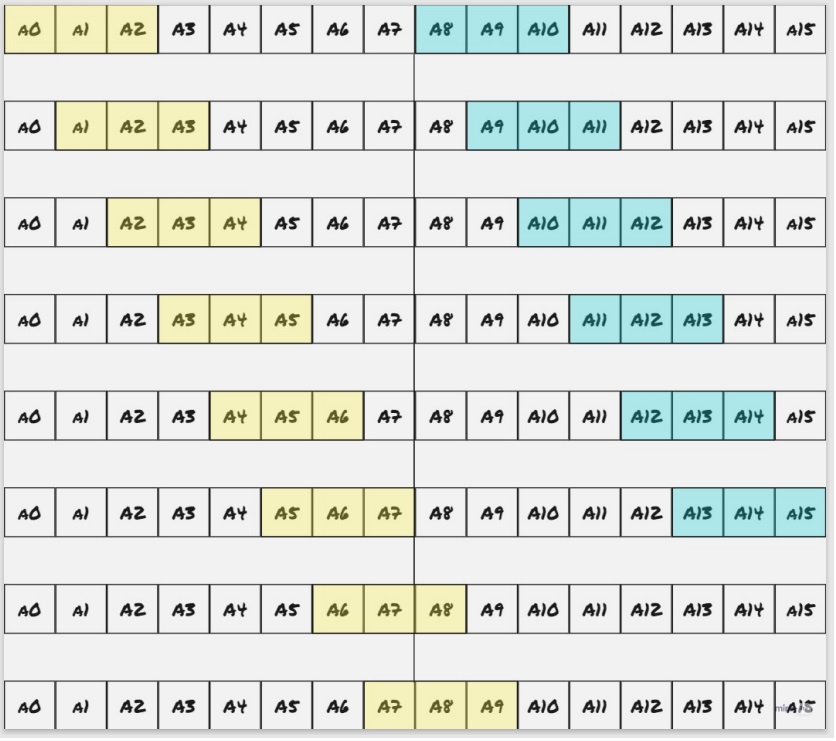
In practice, the input length is much larger than the target window size, so this is not a very high cost to pay.
Spinning up a thread pool doesn’t seem in keeping with the spirit of the exercise. But as we just discovered, even a single core has plenty of extra capacity. So if we just simply issue the two hash code computations in a single thread, we should still be able to take advantage of all of the OOO-superscalar features of modern processors. And indeed we see a dramatic speedup.
This runs at 1.25 GB/s.
How far can we push this approach? At least on our test host, doubling from 2 independent hash codes to 4 yielded no benefits, but YMMV.
Making it Streaming Friendly
Processing the data in this way introduces a very big shortcoming: the algorithm can no longer be applied to a single stream (because we need to be able to seek halfway through the input). I can imagine plenty of use cases where that would be a dealbreaker. How can we get that behavior back? The best approach I can think of is to read a fairly large chunk of data, say some constant \(C\) windows’ worth, for \(C\) around 10 or so. Then process that chunk in “parallel” as described above. Then read and process the next chunk. Now, instead of processing an extra window once, we process two extra windows per chunk (one in the middle and one at the end), and we have to hold \(C\) windows in memory. So the memory consumption is \(O(C*W)\), and the runtime is \(O(N*(1+\frac{2}{c}))\). By playing with the constant \(C\), we can trade off memory consumption and runtime overhead. We get back a streaming-friendly algorithm, which I call the chunked streaming algorithm, and the performance doesn’t suffer too much. For \(C=32\), we can process the input at 1.20 GB/s.
SIMD
One nice feature of this approach is that is very easily adapted to the Intel AVX2 instructions. Instead of splitting each chunk into 2 parts, we can split each chunk into 8 parts, which I’ll call “slices” (each AVX2 register consists of 8 32-bit values), and process each part independently within a single 32-bit slice.
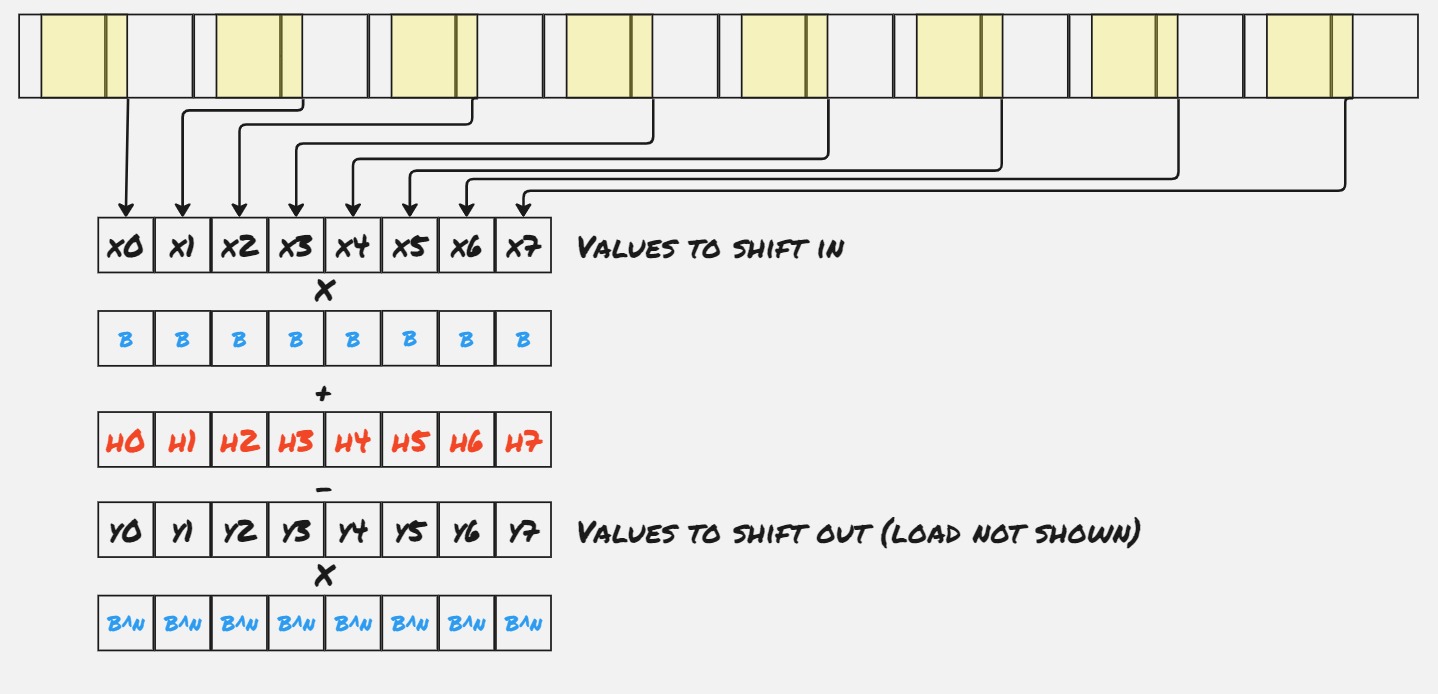
Note that in the code below, in each loop iteration we read 4 values per slice (so 32 in total), and explicitly unroll the loop. This lets us issue only two gathers per iteration, which is a big savings.
static inline __m256i constant_ymm(uint32_t x) {
return _mm256_set_epi32(x, x, x, x, x, x, x, x);
}
// Byte extractors
static inline __m256i byte0(__m256i bytes) {
return _mm256_srai_epi32(_mm256_slli_epi32(bytes, 24), 24);
}
static inline __m256i byte1(__m256i bytes) {
return _mm256_srai_epi32(_mm256_slli_epi32(bytes, 16), 24);
}
static inline __m256i byte2(__m256i bytes) {
return _mm256_srai_epi32(_mm256_slli_epi32(bytes, 8), 24);
}
static inline __m256i byte3(__m256i bytes) {
return _mm256_srai_epi32(bytes, 24);
}
__attribute__ ((noinline))
size_t karprabin_rolling4_chunked_streaming_8x4_avx2(const char *data, size_t len, size_t N, uint32_t B, uint32_t target) {
uint32_t BtoN = 1;
for (size_t i = 0; i < N; i++) {
BtoN *= B;
}
size_t counter = 0;
size_t subblock_size = 4 * N;
size_t block_size = 8 * subblock_size;
__m256i targets = constant_ymm(target);
__m256i bs = constant_ymm(B);
__m256i bns = constant_ymm(BtoN);
__m256i offsets = _mm256_set_epi32(
7 * subblock_size,
6 * subblock_size,
5 * subblock_size,
4 * subblock_size,
3 * subblock_size,
2 * subblock_size,
subblock_size,
0
);
__m256i hashes = _mm256_setzero_si256();
const char* block_start = data;
while ((block_start - data) + block_size + N < len) {
// Initialize hashes
hashes = _mm256_setzero_si256();
for (size_t i = 0; i < N; i++) {
__m256i as = _mm256_srai_epi32(
_mm256_slli_epi32(
_mm256_i32gather_epi32((const int *) (block_start + i), offsets, 1),
24
),
24
);
hashes = _mm256_add_epi32(
_mm256_mullo_epi32(hashes, bs),
as
);
}
uint32_t first = _mm256_extract_epi32(hashes, 0);
if (first == target) {
counter++;
}
for (size_t i = 0; i < subblock_size; i+=4) {
// Values to be added in
__m256i as = _mm256_i32gather_epi32(
(const int*) (block_start + i + N),
offsets,
1
);
// Values to be dropped off
__m256i ans = _mm256_i32gather_epi32(
(const int*) (block_start + i),
offsets,
1
);
// Value 0
hashes = _mm256_sub_epi32(
_mm256_add_epi32(
_mm256_mullo_epi32(hashes, bs),
byte0(as)
),
_mm256_mullo_epi32(byte0(ans), bns)
);
counter += __builtin_popcount(_mm256_cmpeq_epi32_mask(hashes, targets));
// Value 1
hashes = _mm256_sub_epi32(
_mm256_add_epi32(
_mm256_mullo_epi32(hashes, bs),
byte1(as)
),
_mm256_mullo_epi32(byte1(ans), bns)
);
counter += __builtin_popcount(_mm256_cmpeq_epi32_mask(hashes, targets));
// Value 2
hashes = _mm256_sub_epi32(
_mm256_add_epi32(
_mm256_mullo_epi32(hashes, bs),
byte2(as)
),
_mm256_mullo_epi32(byte2(ans), bns)
);
counter += __builtin_popcount(_mm256_cmpeq_epi32_mask(hashes, targets));
// Value 3
hashes = _mm256_sub_epi32(
_mm256_add_epi32(
_mm256_mullo_epi32(hashes, bs),
byte3(as)
),
_mm256_mullo_epi32(byte3(ans), bns)
);
counter += __builtin_popcount(_mm256_cmpeq_epi32_mask(hashes, targets));
}
block_start += block_size + 1;
}
// Deal with what's left over
size_t last_end = (block_start - data) + N - 1;
uint32_t hash = _mm256_extract_epi32(hashes, 7);
for (size_t i = last_end; i < len; i++) {
hash = hash * B + data[i] - BtoN * data[i - N];
if (hash == target) {
counter++;
}
}
return counter;
}
This runs at 1.59 GB/s.
Optimizing Further
The SIMD operations make things much faster, but frustratingly, we are again bound on the chain dependency between multiplying the hashcodes by \(B\). In some sense, we are a victim of our success here. By combining the separate multiplications into a single instruction, we freed up formerly occupied execution ports. But it would be nice to remove this bottleneck. One approach (which I have not tried) is to do the same trick as before, and process two of these parts in parallel.
Another (which we will go with) is to notice that while the multiplication instruction (vpmulld) has a latency of 10 cycles, the processor can issue that instruction every 0.66 cycles. Put another way, issuing a bunch of SIMD multiplications in a row is not much more expensive than issuing a single one.
Recasting the problem
To take advantage of this fact, let’s recast the problem slightly. In our current implementation, we compute the hash over each window and then compare it to the target:
\[H_n := hash\ of\ chars\ [n, ..., n+w-1]\] \[\begin{align*} &H_0 = a_0B^{w-1}+&&a_1B^{w-2}+a_2B^{w-3}+...+a_{w-1} \\ &H_{1} = &&a_1B^{w-1}+a_2B^{w-2} \ \ +...+a_{w-1}B\ \ +a_{w} \end{align*} \\ ... \\ H_{n+1} = B*H_{n}+a_{n+w} - B^wa_{n}\]We did this because it makes the recurrance very straightforward to calculate. But we could just as easily have reversed things:
\[\begin{align*} &H_0 = a_0+&&a_1B+a_2B^2+...+a_{w-1}B^{w-1} \\ &H_{1} = &&a_1\ \ \ +a_2B \ \ +...+a_{w-1}B^{w-2}\ \ +a_{w}B^{w-1} \end{align*} \\ ...\]Assuming that \(B\) is odd, we can compute the multiplicative inverse \(B^{-1}\), and compute the hash with the recurrance:
\[H_{n+1} = B^{-1}(H_n - a_n) + B^{w-1}a_{n+w}\]We still need to multiply that hash in each loop iteration. What would happen if we did not scale them in each loop iteration?
\[\begin{align*} &H_0 = a_0+&&a_1B+a_2B^2+...+a_{w-1}B^{w-1} \\ &H_{1} = &&a_1B+a_2B^2 +...+a_{w-1}B^{w-1}\ \ +a_{w}B^{w} \end{align*} \\ ... \\ H_{n+1} = H_{n}+a_{n+w}B^{n+w} - B^{n}a_{n}\]This is just the result of taking rolling sums of the power series:
\[\begin{align*} &a_0+a_1B+a_2B^2+a_3B^3+a_4B^4+a_5B^5+a_6B^6... \\ &|-----H_0-------| \\ &\ \ \ \ \ \ \ \ |-------H_1-----| \\ &\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ |--------H_2-----| \\ & \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ ... \end{align*}\]At first, this may not seem particularly useful, but it’s easy to see that the new hash \(H'\) and old hash \(H\) are related by:
\[H_n'=H_n*B^n\]And thus:
\[H_n=target \ \iff \ H_n'=target*B^n\]So to determine if the hash matches the target, we just need to scale the target by \(B^n\), before comparing them.
Why is this an improvment? While we (paradoxically) actually have to compute more multiplications, we have gained something, namely that the multiplications can now all be issued at the same time. To illustrate this, let’s consider the non-SIMD case. I’ve grouped instructions at the earliest cycle where they could execute. In practice, they will probably execute later, when an execution port becomes available. Values in registers are represented by diamonds. As before, I’ve highlighted the chain dependency:
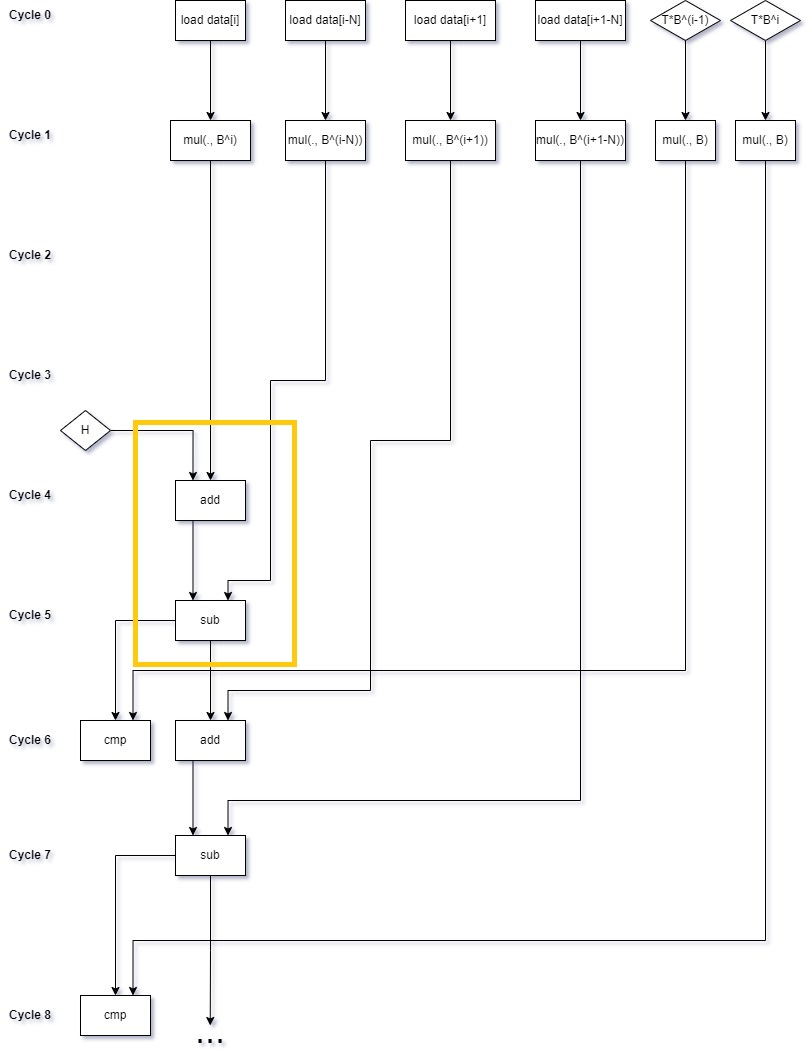
We can see that the chain dependency has gone from a multiplication, addition and subtraction to just an addition and subtraction. All of the multiplications can be issued at the beginning of the loop iteration.
This runs at 1.77 GB/s.
Here’s what a non-SIMD version of this approach might look like. To see how the multiplications can be issued at once, I’ve explicitly unrolled the loop (just to a factor of 2):
__attribute__ ((noinline))
size_t karprabin_rolling2_alternate(const char *data, size_t len, size_t N, uint32_t B, uint32_t target) {
size_t counter = 0;
uint32_t B2 = B*B;
uint32_t BtoN = 1;
for (size_t i = 0; i < N; i++) {
BtoN *= B;
}
uint32_t hash = 0;
for (size_t i = 0; i < N; i++) {
hash = hash * B + data[i];
}
// This is always equal to B^i
uint32_t shift_in0 = 1;
// This is always equal to B^(i+1)
uint32_t shift_in1 = shiftin_0 * b;
// This is always equal to B^(i-N)
uint32_t shift_out0 = 1;
// This is always equal to B^(i-N+1)
uint32_t shift_out1 = B;
// This is always equal to target * B^(i-N)
uint32_t target0 = target;
// This is always equal to target * B^(i-N+1)
uint32_t target1 = target * B;
if (hash == target) {
counter++;
}
size_t i = N;
for (; i + 1 < len; i += 2) {
hash = hash + shift_in0 * data[i] - shift_out0 * data[i - N];
if (hash == target0) {
counter++;
}
hash = hash + shift_in1 * data[i+1] - shift_out1 * data[i - N + 1];
if (hash == target1) {
counter++;
}
// Update the shift factors and targets
// They are multiplied by B^2 because the loop is unrolled with a factor of 2
// Note that all of these instructions can be issued at once
shift_in0 *= B2;
shift_in1 *= B2;
shift_out0 *= B2;
shift_out1 *= B2;
target0 *= B2;
target1 *= B2;
}
// ...
// Deal with any remaining elements
// ...
return counter;
}
A final optimization
There’s one more optimization I’d like to discuss. I don’t really like it, because it makes the method much less useful, but we can do a bit better at counting the number of matches. Instead of counting up hash matches in a single accumulator, we can keep track of the number of matches in each “slice”, and then sum them up at the end. That is, replace:
size_t counter = 0;
// ...
counter += __builtin_popcount(_mm256_cmpeq_epi32_mask(hashes, targets));
// ...
return counter;
with:
__m256i counts = _mm256_setzero_si256();
// ...
matches = _mm256_srli_epi32(_mm256_cmpeq_epi32(hashes, targets), 31);
counts = _mm256_add_epi32(counts, matches);
// ...
return _mm256_extract_epi32(counts, 0)
+ _mm256_extract_epi32(counts, 1)
+ ...;
_mm256_cmpeq_epi32 fills the corresponding 32-bit value with 0xFFFFFFFF if the values match, so shifting by 31 will result in a 1 in the slice if the hash matches the target.
The reason I don’t like this is that while _mm256_cmpeq_epi32_mask produces an output that can be used for actual string search, I cannot think of a good use case for simply counting the number of hash matches. But it was an interesting optimization, so I left it in.
This runs at 1.86 GB/s.
Update: A commenter on HackerNews points out that 0xFFFFFFFF is just -1 in two’s complement arithmetic, there’s no need to shift. Instead, just do this:
__m256i counts = _mm256_setzero_si256();
// ...
matches = mm256_cmpeq_epi32(hashes, targets);
counts = _mm256_sub_epi32(counts, matches);
// ...
return _mm256_extract_epi32(counts, 0)
+ _mm256_extract_epi32(counts, 1)
+ ...;
This yields a modest improvement, to 1.89 GB/s.
Summary
All in all, we were able to achieve a greater than 2.5x speedup. It was interesting to poke around the AVX instructions after a while away from them, and I definitely feel like I have a better intuition for these kinds of problems after working through this. Thanks to Daniel Lemire for posing the problem and providing his benchmark harness.